
- Today
- Total
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 파이썬 입문
- 채용문제
- 코딩문제
- 알고리즘 강좌
- 알고리즘
- 코딩시험
- 셀레니움
- 파이썬활용
- 파이썬
- c언어
- 파이썬 알고리즘
- 파이썬 강좌
- 자료구조 강의
- 자료구조
- 대학시험
- 면접 파이썬
- 쉬운 파이썬
- python data structure
- 알고리즘 강의
- Crawling
- 파이썬 강의
- python 중간고사
- 프로그래밍
- gdrive
- 크롤링
- 기말시험
- selenium
- 파이썬 자료구조
- 중간시험
- 파이썬3
반원 블로그
03c. 속도 기준 알고리즘 비교 본문
속도로 분석하는 과정
생각보다 단순합니다.
- 연산 횟수를 셉니다.
- 1과 처리해야 되는 데이터 수에 대한 관계를 분석합니다.
- 2를 통해 관계식(또는 함수) T(n)을 세웁니다.
최악의 상황을 분석하자.
복잡한 동전 지갑에서 눈을 가리고 500원을 찾는다고 가정하자. 이 때의 최선, 평균, 최악의 경우를 적어보면 다음과 같습니다.
- 최선 : 첫 동전부터 500원!
- 평균 : 반절정도 꺼냈을 때 500원을 발견!
- 최악 : 처음부터 500원은 있지 않았다...
최선의 경우를 분석해봤자 별 의미는 없겠죠. 단순히 "운이 좋았다"로 정리할 수도 있습니다.
결론적으로 말해서 알고리즘을 분석할 때 최악의 경우(Worst Case)으로 상황을 둡니다. 알고리즘 이용자 입장에서는 발생 빈도가 높은 평균의 경우(Average Case)를 성능 분석한 결과가 더 필요할 수 있습니다.
하지만 이건 결과만을 생각한 의견입니다. 과정을 고려하지 못했습니다. 평균의 경우의 성능 분석은 "어떤 상황이 평균으로 둘 것인가?"에 대한 이슈를 해결해야합니다. 알고리즘에 따라서 평균적인 상황을 정의하기 어렵거나 논란이 있을 수 있습니다.
그러나 최악의 경우는 대부분 정의가 가능하고, 확실한 정의가 힘들더라도 각 정의의 오차가 적습니다.
처리 데이터가 많은 상황을 분석하자.
처리할 데이터의 개수에 따라 연산 횟수가 급격하게 늘어나서 알고리즘의 속도가 느려질 수 있습니다.
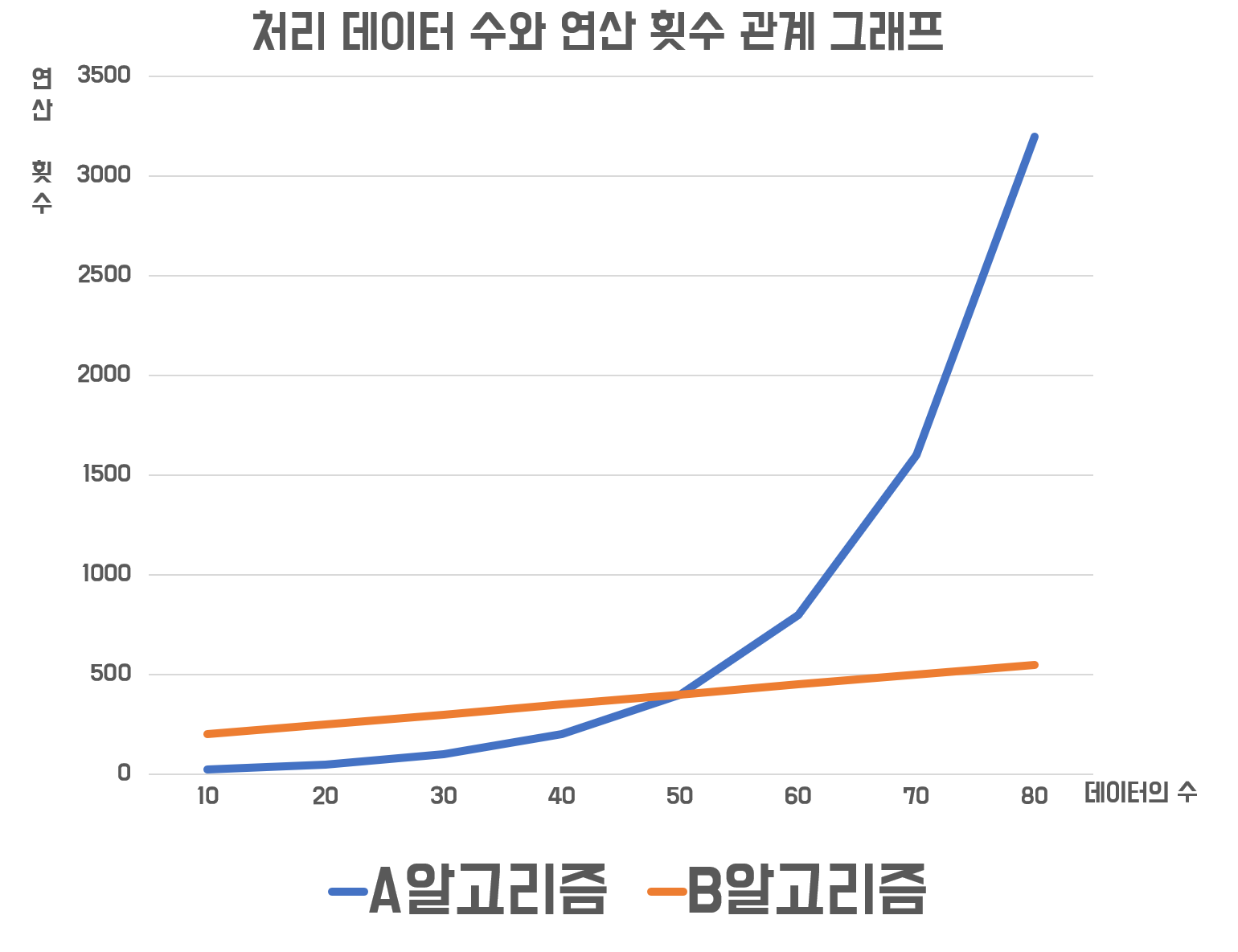
어느 알고리즘이 좋다고 할 수 있을까요? 두 선이 만나기 직전까지는 알고리즘A가 좋고, 그 이후는 알고리즘 B가 성능이 좋네요.
그럼 이렇게 생각할 수 있습니다. "초반에는 알고리즘 A를 사용하고, 그 이후엔 알고리즘 B를 사용한다!" 그렇다면 알고리즘을 2개 구현해야겠네요?
보통 알고리즘은 하나 구현합니다. 또한 데이터가 적을 때 이득은 적은 편이지만 데이터가 많을 때의 손해는 굉장히 큽니다. 따라서 이 경우엔 "알고리즘 B가 A보다 좋다"라고 평가할 수 있습니다.
하지만 프로그램 특성상 처리할 데이터가 적거나, 두 알고리즘이 만나는 지점보다 적은 데이터만 관리한다면? 그 때는 알고리즘 A를 사용해야겠죠.
위키독스 연재 : https://wikidocs.net/book/2868
'2018~ > 파이썬 자료구조 알고리즘' 카테고리의 다른 글
| 03d. 시간 복잡도 계산과 빅오(Big-Oh) 표기법 (0) | 2019.05.10 |
|---|---|
| 03b. 성능 분석의 기준 (0) | 2019.05.08 |
| 03. 성능분석 기법 (0) | 2019.05.07 |
| 03a.자료구조와 알고리즘 (0) | 2019.05.07 |
| 02c. 이중 연결 리스트(doubly linked list) - v. 탐색 (0) | 2019.05.06 |
| 02c. 이중 연결 리스트(doubly linked list) - iv. 삭제 (0) | 2019.05.05 |
| 02c. 이중 연결 리스트(doubly linked list) - iii. 출력 (0) | 2019.05.04 |
| 02c. 이중 연결 리스트(doubly linked list) - ii. 삽입 (0) | 2019.05.03 |
